



股票预测是真的吗 股票预测可信吗
股票预测是真的吗 股票预测可信吗
假设股票可以被精确预测,那就必须有一个前提,股票未来走势具备某种确定性,必然性,否则就无法被精确预测。事实上,当你预测股票未来会上涨,从而买入股票,这个买入的行为已经影响了股票的走势,股票在你买入之后的状态,和你买入之前的状态已经不一样。
个人的力量还不足以改变市场,但股票是所有交易者的合集,在下一秒钟,大量的交易者参与了交易,股票的状态就会因此发生重大的改变,上一秒钟你预测股票要上涨的结论可能就已经不成立了。
预测的行为,会改变预测的结果,导致结果变得无法被精确预测。
市场上随时都有人在做买卖,这会随时改变市场的状态,市场就是一个不断动态演变的过程,而不是沿着既定轨迹走的过程,这使得市场变得无法精确预测。
例如当很多人开始认为某个股票还要继续上涨的时候,就会大量的买入该股票,而大量买入该股票的行为会导致该股票涨的比预测的更高,而股票的上涨会加强这种预测的思维,导致多头更强烈的买入,形成了一个加强效应。
同理,当大部分人认为某个股票要下跌的时候,就会卖出该股票,导致该股票跌的更多。
预测改变股票走势的特性也并不只是加强效应,还会有逆反的作用,例如当大部分人认为某个股票还要继续上涨,并且都已经大量持有了该股票之后,此时大家的信心到了最鼎盛的时期,股价也就到顶了,因为大家手里都是股票,已经没有现金可以买入。
特别是在牛市顶部阶段,这种现象特别明显,牛市顶部的时候,也就是多头力量最强盛的时候,大家普遍都认为股票还要上涨,所以都选择了持有股票,没有现金了。此时然市场上都是多头,已经没有买盘,再也无力买上去,后面自然就要下跌了。
使用LSTM-RNN建立股票预测模型
硕士毕业之前曾经对基于LSTM循环神经网络的股价预测方法进行过小小的研究,趁着最近工作不忙,把其中的一部分内容写下来做以记录。
此次股票价格预测模型仅根据股票的历史数据来建立,不考虑消息面对个股的影响。曾有日本学者使用深度学习的方法来对当天的新闻内容进行分析,以判断其对股价正面性/负面性影响,并将其与股票的历史数据相结合,各自赋予一定的权重来对近日的股价进行预测[1]。该预测方法取得了一定的效果。
而这里我没有引入消息面的影响,主要出于以下几点考虑:
1.消息的及时性难以保证:很多时候,在一只股票的利好/利空消息出来之前,其股价已经有了较大幅度的增长/下跌。信息的不对称性导致普通群众缺乏第一手消息源。
2.消息的准确性难以保证:互联网上信息传播速度极快,媒体之间经常会出现相互抄袭新闻的情况,而这种抄来的新闻(非原创新闻)往往没有经过严格的审核,存在着内容虚假,夸大宣传的可能性。一旦分析模型错用了某条谣言或真实性不高的新闻,很有可能得出错误的预测结果。
3.语言的歧义性:一条新闻,其正面性/负面性往往存在着多种解读。例如“习主席宣布中国将裁军30万”——新华每日电讯2015.09.04。这条新闻一般意义上可以解读为:中央政府深入推进改革,精兵简政,大力发展国防军工事业。这是一种正面性的解读。而在使用机器学习模型时,如传统的奇异值分解算法(SVD),很有可能会判定其与“去年五大行裁员近3万”这种新闻具有较高的相似度,因而将其划分为负面新闻。
4.技术实现较为繁杂:这其实是一个非常重要的原因啦~,获取正确的信息并进行NLP操作,往往需要经过以下流程:人工浏览网页确定稳定可靠的信息源→设计爬虫实现有效信息的获取→设计新闻裁剪(填充)方案以应对不同长度的新闻→人工标注新闻的正/负性(也可以用当日股价涨跌来标注)→设计网络模型→训练及验证模型。其中的每一步都非常麻烦耗时,而且对于个股来说,并不是每天都会有新闻出现。
上面说了这么多,还没有开始对我这个预测模型进行介绍,下面开始进入正题。在决定排除消息面的考量之后,我开始思考股价涨跌的本质,我认为股价就是资金博弈结果的体现。这次建立的预测模型,朴素的想法是通过深度学习模型来洞悉庄家的操作规律,对拉升、砸盘的情况进行预测。为了达到以下目的,我决定选取以下七个特征来构建网络模型,即:
涨跌幅 最高涨幅 最低跌幅 大单净流入 中单净流入 小单净流入 换手率
使用这七个特征来对股票的涨跌情况以及资金的流动情况建立适当的模型。此外,其他的指标类似MACD、均线等也是通过一些基础数据的运算得出,在构建模型时并没有将其纳入考量范围。
一.源数据及其预处理
通过某股票交易软件,我获得的源数据约有20来个特征,包括:涨幅、现价、涨跌、买入、卖价、成交量等等。为了得到上面所述的七种特征,挑选出涨跌幅、大单净流入、中单净流入、小单净流入、换手率这5个特征,并计算最高涨幅、最高跌幅两个特征。通过下列公式计算获得。
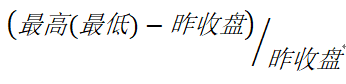
经过处理的股票特征数据存储在 股票名.csv文件中,类似下图:

图中的特征顺序为:日期,大单净流入,中单净流入,小单净流入,涨跌幅,最高涨幅,最高跌幅,换手率,股价。股价在这里的用处是拼接训练样本输出时,计算多日的总涨跌幅。
注:在对源数据进行处理的时候,经常会遇到空值问题:即,有些特征值为0的时候,系统给出的源数据为”-”或”“。需要进行特殊处理。(经常遇见新股第一天的涨跌幅为空,或某交易日大单净流入为空。)
1 if fin_temp.ix[day,12]=='-' or fin_temp.ix[day,12]=='': # 新股的涨跌幅一栏会出现'','-',需要特殊处理
2 raise_value = 0.0
3 else:
4 raise_value = float(fin_temp.ix[day,12])
二.训练样本拼接
首先设置一个滑动窗口,本次实验中将滑动窗口设置为50个交易日。每一个训练样本由50个连续的交易日组成,每个交易日的数据包含上述的七个特征,即一个50*7的矩阵,而一个样本的输出则是三个交易日之后的收盘价对比今日(即样本的输入中最后一个交易日)收盘价的涨跌幅,设置其上限为0.3,下限为-0.3(当然,连续三个涨停板的涨幅会超过0.3,这里将其统一视作0.3)。之所以选择三个交易日之后的涨跌幅作为训练样本的输出,是因为我国股市是T+1操作规则,当日买入不可卖出,预测的稍微靠后一些可留有操作空间;再有就是一天的拉升/砸盘偶然性太大,不易预测,对稍微长期一点的状况进行预测有着更高的稳定性。
归一化相关工作:因为神经网络激活函数的限制,需要在训练前将数据映射到0~1区间。本次试验中,对近两年的数据,获取其各项特征的最大值与最小值。设置归一化与函数,在样本拼接的同时将数据进行归一化。
样本 输入的归一化:
1 def normalize_oneday(stockN,fdata,day):
2 max_min = list(max_min_list[stockN])
3 in_1 = (fdata.ix[day,1]-max_min[1])/(max_min[0]-max_min[1])
4 in_2 = (fdata.ix[day,2]-max_min[3])/(max_min[2]-max_min[3])
5 in_3 = (fdata.ix[day,3]-max_min[5])/(max_min[4]-max_min[5])
6 in_4 = (fdata.ix[day,4]-max_min[7])/(max_min[6]-max_min[7])
7 in_5 = (fdata.ix[day,5]-max_min[9])/(max_min[8]-max_min[9])
8 in_6 = (fdata.ix[day,6]-max_min[11])/(max_min[10]-max_min[11])
9 in_7 = (fdata.ix[day,7]-max_min[13])/(max_min[12]-max_min[13])
10 return [in_1,in_2,in_3,in_4,in_5,in_6,in_7]
样本 输出的归一化与反归一化:
def normalize_raise(volume):
norm_value = (volume+0.3)/0.6
if norm_value>1:
norm_value = 1 #涨跌幅超过30%的都定义为 1或0
elif norm_value<0:
norm_value = 0
return norm_value
def denormalize_raise(value):
volume = value*0.6-0.3
return volume
设置滑动窗口sample_window = [],每次遍历一行特征数据,归一化后插入窗口末尾,当窗口大小满50时,计算3天后涨跌幅,拼接出一个训练样本,并将sample_window中第一个交易日的值弹出。
1 normalized_daily_sample = normalize_oneday(stockN_list_str[i],fin_temp,day)
2 # TODO 给样本插入该日数据
3 sample_window.append(normalized_daily_sample) #存入一个样本list,特征数为7,全部归一化完毕
4 if len(sample_window)==window_len: # 窗口大小满50
5 #TODO 需要对涨幅进行归一化 暂定 30% TODO
6 raise_3days = normalize_raise(float(fin_temp.ix[day+3,8])/float(fin_temp.ix[day,8])-1.0)
7 samples.append([sample_window,raise_3days])
8 sample_window = sample_window[1:]
遍历完所有数据行后,获得数百个训练样本。并将训练样本转存为numpy.array格式以方便训练。
注:跳点问题,具体分为除权(涨跌幅超过10%)与停盘(相邻交易日间隔超过10天)。对于跳点问题,我们判断其是否发生,一旦发生跳点,就清空sample_window,从下一个交易日重新开始计算样本输入,以杜绝样本输入中有跳点数据。
1 # 间隔日期大于10天,即day+3大于12天,判断为有停盘,不连续,或者涨跌幅异常(超过10.5%),不能作为训练样本序列,
2 if int(diff/(24*3600))>12 or abs(raise_value)>10.5:
3 sample_window = []
三.搭建模型
这里使用keras深度学习框架对模型进行快速搭建。建立Sequential模型,向其中添加LSTM层,设定Dropout为0.2,加入Dense层将其维度聚合为1,激活函数使用relu,损失函数定为交叉熵函数。之前也使用过传统的sigmoid作为激活函数,但经实验感觉效果不如relu。
1 model = Sequential()
2 model.add(LSTM(128, input_shape=(window_len,7), return_sequences=False)) # TODO: input_shape=(timesteps ,data_dim)
3 model.add(Dropout(0.2))
4 model.add(Dense(1))
5 model.add(Activation('relu'))
6 model.compile(loss='binary_crossentropy',optimizer='rmsprop',metrics=['accuracy'])
模型搭建完毕,使用之前获得的数百个训练样本展开训练,并保存模型。
1 hist = model.fit(trainX,trainY,batch_size=1,epochs=50)
2 score = model.evaluate(trainX, trainY, batch_size=10)
3 if os.path.exists('./model/'+file_name[:-5]):
4 model.save('./model/'+file_name[:-5]+'/model_%s_%s.h5'%(window_len,date)) # HDF5 保存模型
5 else:
6 os.mkdir('./model/'+file_name[:-5])
7 model.save('./model/'+file_name[:-5]+'/model_%s_%s.h5'%(window_len,date))
四.效果展示
最初的时候,我对所有的股票的训练样本堆叠到一起,训练出一个大模型(貌似当时有9万多个训练样本,整整训练了一天=,=),之后对每个股票都进行预测,企图找出次日涨幅最高的前5支股票。后来发现根本做不到……每支股票的操作规律都不一样,使用单个模型无法有效的把握个股的涨跌趋势。
之后,我单独选了中国软件这个股票(这个票看起来像庄家主导的那种),对它单独进行分析。使用了一年半的交易数据作为训练集,共有293个训练样本,训练140个epoch。最后训练出模型对测试集中的60个测试样本进行验证。预测误差如下图。

其中前40个是训练集中的样本,我们使用其输入部分进行预测,发现预测结果贴合十分紧密;后60个是我们测试集的样本,我对其预测效果还是比较满意的,大跌、大涨基本都有预测到,除了第67到第75个点那一波大跌预测的不好。随后我使用模型进行模拟交易,设定初始资金两万元,在预测三天后会上涨时买入,预测三天后会下跌时卖出,均以收盘价为交易价格,买入时扣除万分之2.5的佣金。收益曲线如下,蓝色线条代表按模型进行交易的收益,绿色线条代表一直持有股票的收益。
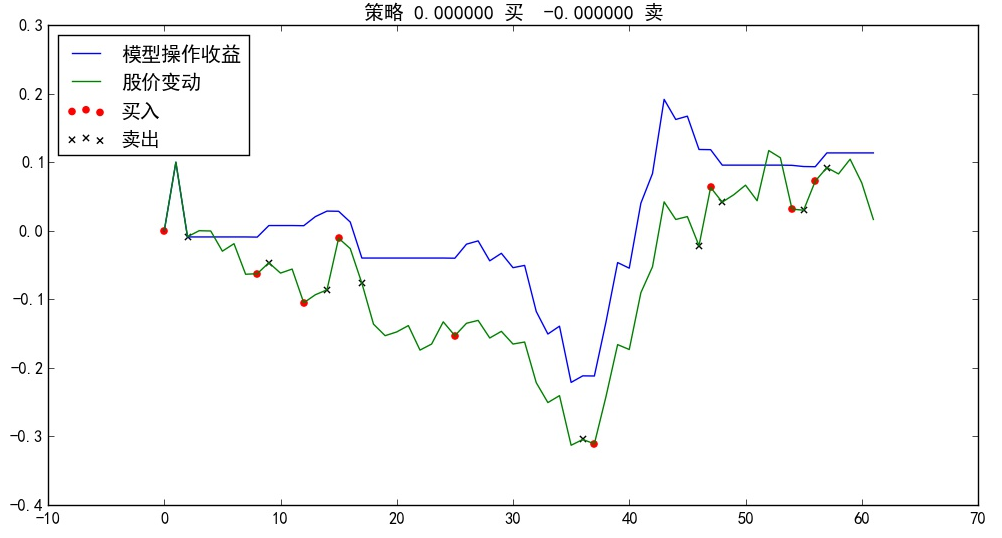
可以看出,模型的预测效果还是不错的。尤其是开始的20多个点,能够较为准确的避开一波回调下跌。
但我也知道,对模型进行验证的样本数量还是太少,又过了一个月,在额外收集了20个交易日的数据之后,我又对该样本进行了测试。
预测误差:
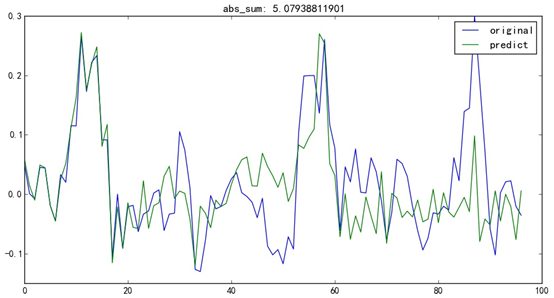
由上图可以看出,倒数20个交易日的这一波大涨幅,模型并没有能够预测到。
收益曲线:
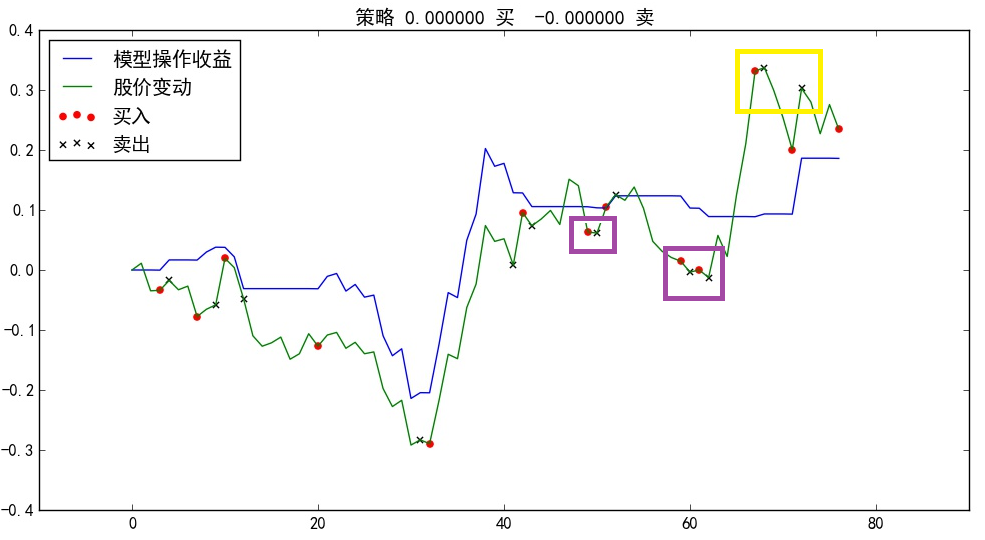
从上图可以看出,在紫色方框圈出来的地方,模型多次预测会有一波涨幅,但紧跟着又立马预测股价要跌,对股票进行了抛售,错过了这两次大涨的机会;在黄色方框圈出的地方,模型两次在顶点做出了准确的预测,精准抛售,躲过两次大跌。
经过股票数据的验证,使用LSTM-RNN来对股票进行预测具有一定的可行性,但效果不佳(要是效果好的话我估计也不会分享到网上,自己闷声发大财啦,哈哈~~~)。
